


The API Bible's New Testament: Aggregators
Where the work is harder, but the moats are often deeper

Before we jump in today, I’d like to give a shout-out to Flexpa, my new employer. If you like these sorts of articles, you should go check them out for two reasons:
They’re a classic example of one of the classifications of API companies we’ll cover today, offering world-class developer tools to applications, providers, and payers that want to embed all of a patient’s claims data into their software.
They pay my salary. Your interest, clicks, and API usage enables me to write this sort of content.
So help me help you. Call me, beep me, if you wanna reach me (to learn about how healthcare’s financial data can empower your digital health or fintech solution.

Well, ladies and gentlemen, aside from the brief interlude above, this is all shot, no chaser. We ride once more back into the deep, jumping to where we finished in the last article to close things out. In that volume, we covered the first two columns of our handy API products chart. Today, we’ll dive into the remaining classifications: open and closed aggregators.

Open aggregators
The next class of API companies are alchemists of sorts, transforming the innate access to content that the Internet itself offers into simple, developer-friendly APIs.

The web has many open resources, content, and functionalities available on the pages that companies create that require no business-to-business relationship to access. Developers often want to utilize these open resources, but are hindered by a few problems:
The resources may not be programmatically available, requiring some sort of RPA screen-scraping to use.
If the resource is available via API from the resource holder, those APIs may vary dramatically, incurring increased development time to deal with heterogeneous formats
The resources may be available only if a consumer has authenticated with their credentials (i.e. logged into a portal)
The resources are generally spread across a wide variety of websites, meaning that the developer may have to spend ongoing effort to create and maintain connections.
Thus the opportunity for open aggregator API companies. They perform the specific hustle of pre-building and maintaining the connections, normalizing disparate content formats, and allowing developers to connect once for widespread access. They use all means necessary - scraping screens, downloading files, using available APIs - and just find a way to get access. They are aggregators as they aggregate the universe of available portals/endpoints/web pages themselves (rather than relying on a pre-existing network) and they are open because they don’t necessarily need business relationships with the content holder to do this aggregation. If this is sounding slightly familiar, it’s because we’ve talked about (but not formally categorized) this style of API company in Indiana Jones and the Personal Health Record.
Compared with on-ramp companies, there’s more of an intrinsic moat to this work. If I’ve connected to thousands of bank portals, an aspiring copycat has to play quite a bit of catchup to reach that same breadth and spend a lot of calories to ensure those connections don’t break. However, it’s not insurmountable - it is just a matter of hard work to stand up a competitor company, track down the portal endpoints/web pages, and build out connectivity.
One strategy often seen from these companies to mitigate this risk is to use the aggregate demand and data flowing through to create new products aimed at the data holder side. By building such products (or otherwise negotiating unique deals with data holders), they cement themselves in hard-to-replicate partnerships for unique or exclusive access with content holders.
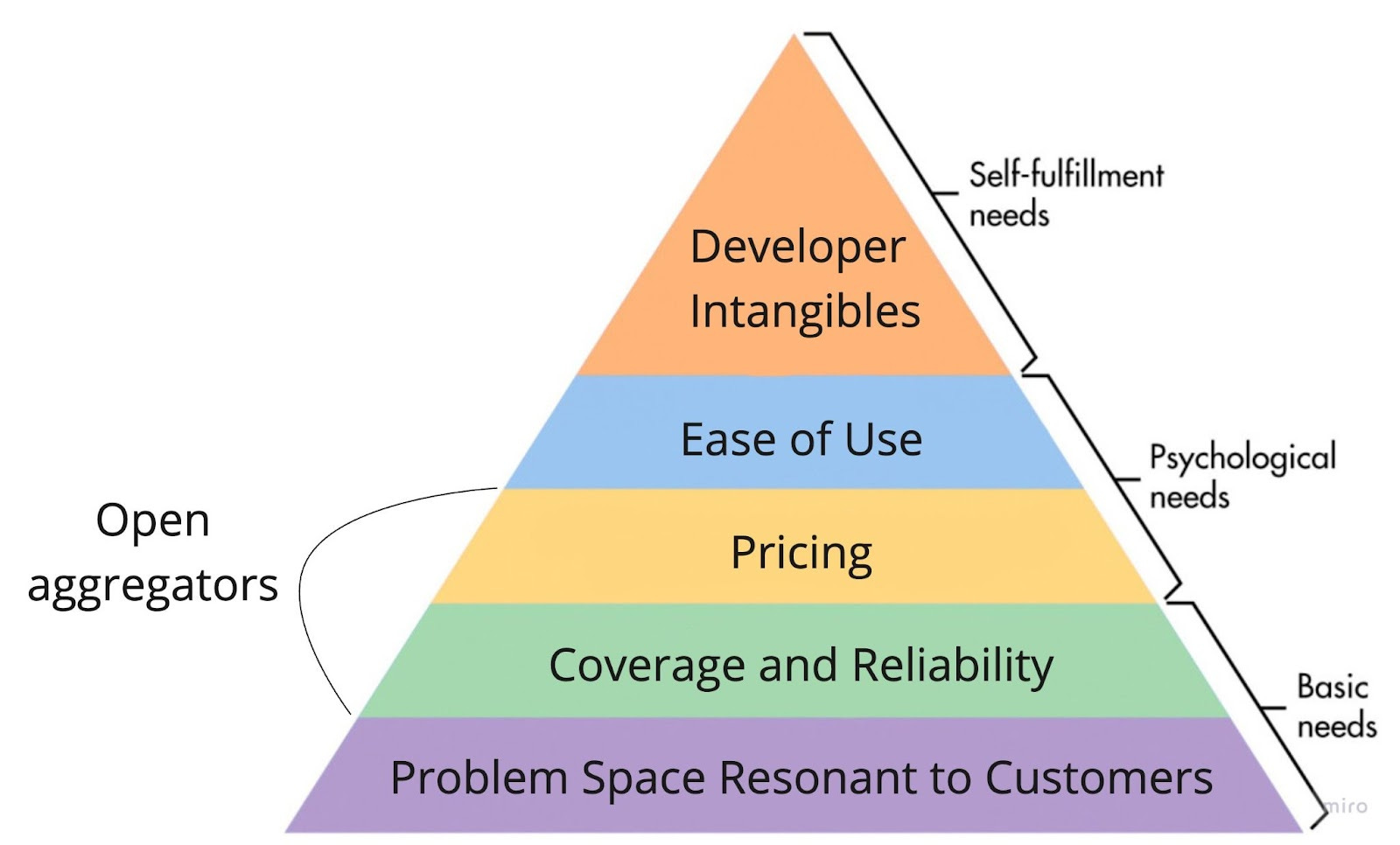
Open aggregators are in the specific business of collecting and consolidating widely available, proven solutions, so the problem space is already resonant to customers. But in that quest to collect, there’s always a long tail of available portals/endpoints/web pages to be hunted down to differentiate, especially with the unique access inherent to the data holder strategy mentioned above. In this way, coverage and reliability end up being a key battleground for this class of API product, although sometimes they compete at a higher level.
We can broadly divide open aggregator products into two sub-divisions: public content and authenticated content. Public content is generally data that is not tied to a particular consumer, whereas consumer data is tied to an individual. As such, when these API companies are aggregating the latter, they often must rely on the consumer to authenticate (provide their sign-in credentials) to perform their functions or access different data, which can act as a point of friction. Thus, they are logically only sold to and embedded in consumer-facing experiences and products. For public content aggregators, their clientele may be more varied, selling access to aggregate data to consumers, consumer-facing businesses, and pure business-to-business use cases.
Public Content Examples
With any fully open and accessible resource on the Internet, specialized industry-specific aggregators typically arise to provide a single entry point for comparing and contrasting - Yelp for restaurants, Booking.com for hotels, etc. The existential threat for each of these, however, is the granddaddy Internet entry point - Google. Google is by far the most prevalent and successful aggregator, using its high control of consumer demand in order to aggregate supply such as hotels, flights, or general business info.
The time has long since passed when Google simply directed users to the “right answer”. It is now Google’s strategic imperative to amass and embed open resources into their search to maximize the time spent in Google search (and not in Yelp or Booking), thus maintaining the customer relationship and ensuring that the ads you see and the ads you click are theirs and not others.

Thus, most non-Google public data aggregators are not that interesting. They exist and often expose an API for the domain-specific data they collect, but, with the spectre of Google lurking, are often capped on their ceiling or swallowed by the behemoth.
Turquoise Health comes up from time to time as a healthcare API company, though, and distinctly falls into this bucket, as they look to take advantage of price transparency rules that came into effect last year requiring providers to openly list the cost of hospital items or services before patients receive them. Aggregating those costs and exposing them via an API is certainly a valuable product offering; however, that threat of Google performing that same aggregation does loom here. It’s easy to imagine price data embedded alongside the operating hours and reviews in a Google Maps widget. Cleverly, then, they’ve done the bare minimum in terms of an API (basic developer docs via SwaggerHub and Redoc, OpenAPI 2.0 🤮) and focused on creating new, excellent products aimed at the data holder side:

This is unambiguously smart, entrenching them in a way that makes them hard to displace for a sticky, unfun problem (compliance) that Google likely has little stomach for.
Ribbon Health presents another example of this style of API company. First aggregating the various open sources of provider data, such as health plan directories and files like the National Plan and Provider Enumeration System (NPPES) and the Physician and Other Practitioners Public Use File (PUF), they have since worked to differentiate themselves and protect against Google or copycat aggregators by supplementing those open sources with client-contributed provider data and third-party partnerships. They’ve also been diving deeper beyond pure provider data aggregation offering logical next steps one would expect in customer workflows, like eligibility checks.
It’s worth noting that open scheduling if adopted in healthcare, would firmly fall into this category. As noted in The Scheduling Conundrum, this strongly plays to Google’s core competencies, so it’s no wonder they’re actively eyeballing the space.
Authenticated Content Examples
Bank Information
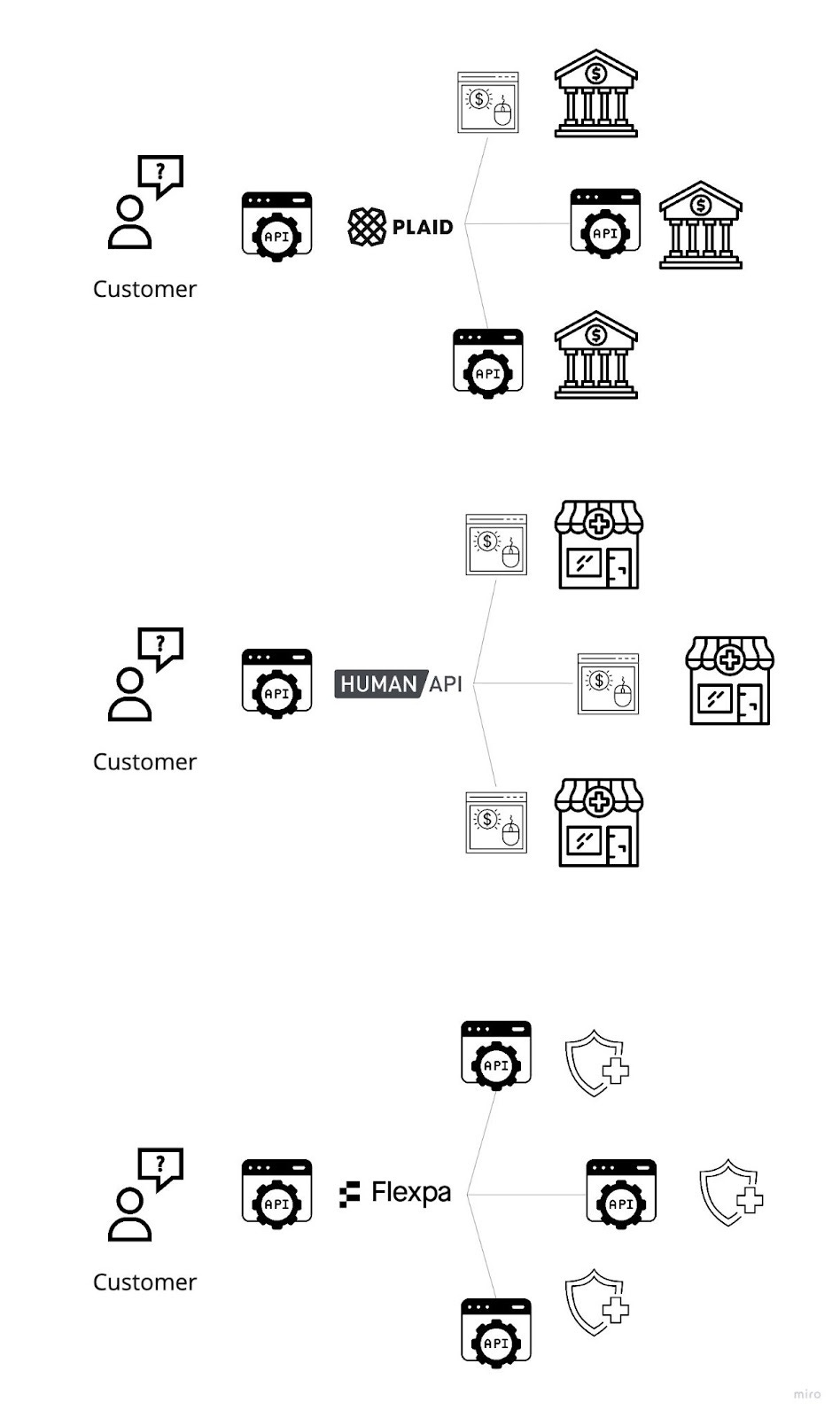
Plaid is now the well-known entity here, but the real OG bank aggregator is actually Yodlee. It was founded in 1999 (before Web 2.0, before fintech, and even before Y2K), and thus is the most obvious example of how the moat of first-mover in open data aggregation is not impregnable. As mentioned before, Plaid was founded in 2013, literally 14 years later, went all-in with a hyper-focus on the developer experience and breadth of connections that was leading at the time and has vastly outpaced Yodlee and other competition (Finicity, MX) in funding, market awareness, and overall success as a result. See here if interested in a little deep dive I did to compare and contrast the services. Aside from Plaid, I think MX is somewhat neat in that it purports to aggregate and overlay the other three companies (and their own connections) to offer a premium superset product with the broadest coverage. I’m not sure if that’s the outcome in practice, but it’s certainly a differentiating go-to-market that could be applied to other industries.
Plaid has internalized the leapfrog lesson they taught Yodlee, for in 2020 they launched Plaid Exchange, a data holder-focused product offering that provides a hard-to-copy moat. For any bank that adopts this tool, Plaid becomes firmly embedded with them in a unique position that cannot be replicated by Yodlee or Finicity, or another competitor. They were even able to go to the vendors that create the core banking systems for financial institutions and have those companies develop it into their software. As a result, sales of that core banking software act as a distribution channel to the banks they service.
Stripe recently made a splash in this part of the fintech world by announcing Financial Connections, direct competition to their former collaborator Plaid. It’s painful to watch that drama, but is an entirely logical move in the abstract - an open aggregator network is a more defensible asset than acting as an on-ramp (and relying on the whims of the credit card networks).
Payroll Data
As my friend Alex writes over at Fintech Takes in “Payroll Data + Fintech”:
A new generation of fintech infrastructure companies are building APIs that can facilitate consumer-permissioned access to the data held in payroll systems like ADP and Paychex.
…
Every fintech company building APIs to access consumer-permissioned data owes a debt to Yodlee, MX, Finicity, and Plaid. The ubiquity of bank transaction data capabilities within B2C fintech apps has (as those apps have grown in popularity) helped familiarize millions of consumers with the process of giving a third party permission to access their personal financial data. It’s easy to forget, but 15 years ago this was a scary thing to do! Bank transaction data aggregators have made it feel safer, which gives payroll API providers a huge leg up.
The road paved by Plaid is a template that now can be (and is being) copied. As Alex notes, payroll shows the foundational financial information, grabbing the income information via an employer portal, and starts the waterfall down to saving, spending, and credit.

As you can see, the consumer-authenticated API company landscape is much more diverse in payroll than in bank information. Argyle seems the most mature offering but has some shady elements. Plaid launched Plaid Income in 2021 but is still in beta. Check out a synopsis I wrote about that fragmented market here if you’re interested in full detail about those companies as well as Atomic, Citadel, and Pinwheel.
Patient Data
As we talked about in the PHR article, health data aggregators have followed closely behind financial aggregators. In the early days of patient portals, companies like HumanAPI and Greenlight Health used government-required functionalities (View, Download, Transmit) to pull CDA documents with rich clinical history from providers after collecting patient credentials. For non-HIPAA entities like life insurers and legal firms, this sort of screen scraping service was quite valuable for their release of information workflows.
The world of open aggregators relying on patient authentication is changing, with companies utilizing new technologies. With the advent of APIs, newer companies like 1up Health and OneRecord have aggregated those provider endpoints to provide more consistency, more security (APIs mean the aggregators don’t have to store credentials), and potentially cleaner data.
We’ve also seen new health data aggregators pushing towards non-provider data sources. Given the CMS Patient Access regulation (more on that here), 1up, OneRecord, and new entrant Flexpa (!!!) have worked to connect to payers’ APIs mandated by the rule. These APIs currently only expose CMS-regulated plans and not commercial lives, but given the wealth of data payers possess and the lower barrier of patients remembering their portal login, the upside here is quite high.
Similar to Plaid with their Plaid Exchange product, 1up has aimed to differentiate from the pure aggregation of patient authentication and uniquely capture the supply side by releasing their FHIR server offering. In contrast to Exchange, though, they’ve seen decently strong adoption, at least on the payer side, as this offering timed well with CMS regulation requiring such capabilities (see the “Operated by 1up for CMS Compliance” column here).
Lastly, a number of wellness aggregators have emerged, connecting to Fitbits, Oulas, and a variety of other devices in order to aggregate and standardize the sleep, activity, and fitness metrics produced by the wide variety of wearables and trackers on the market today. Validic and HumanAPI were the first to build support here, but new players Terra, ROOK, Metriport, WeFitter and Vital purport to offer lower prices and superior developer experience.
Given none of these aggregators do all of the health-relevant sources and have different coverage, there seems to be an opportunity to build an MX equivalent here - aggregating the aggregators, normalizing the experience, and charging for a premium product.
❗Startup Idea Alert ❗
I have to admit, I’m surprised that there aren’t more consumer-authenticated data aggregators across industries. Portals and logins exist for almost everything and screenscraping is easier than ever now that it’s had its sexy rebrand as RPA.
In particular, it feels like a consumer-authenticated aggregator of e-commerce portals could be interesting to give a more fine-grained and complete view of purchase information (especially since we are now seeing the emergence of e-commerce closed aggregators, as we’ll discuss in the next section). I could imagine that level of detail would be great to have for marketers, especially in a post-IDFA world (thanks, Apple). It could also funnel unique data into new-age credit-builder or underwriting fintechs, allowing insights not available via bank transaction data.
Edit: Since writing this article, companies like Knot API and Sunlight have popped up in this vein, allowing consumers to update their card on file across e-commerce vendors they use. While not the use case I articulate above, this might be more compelling - consumers hate to have to update their information across all their websites.
Closed aggregators
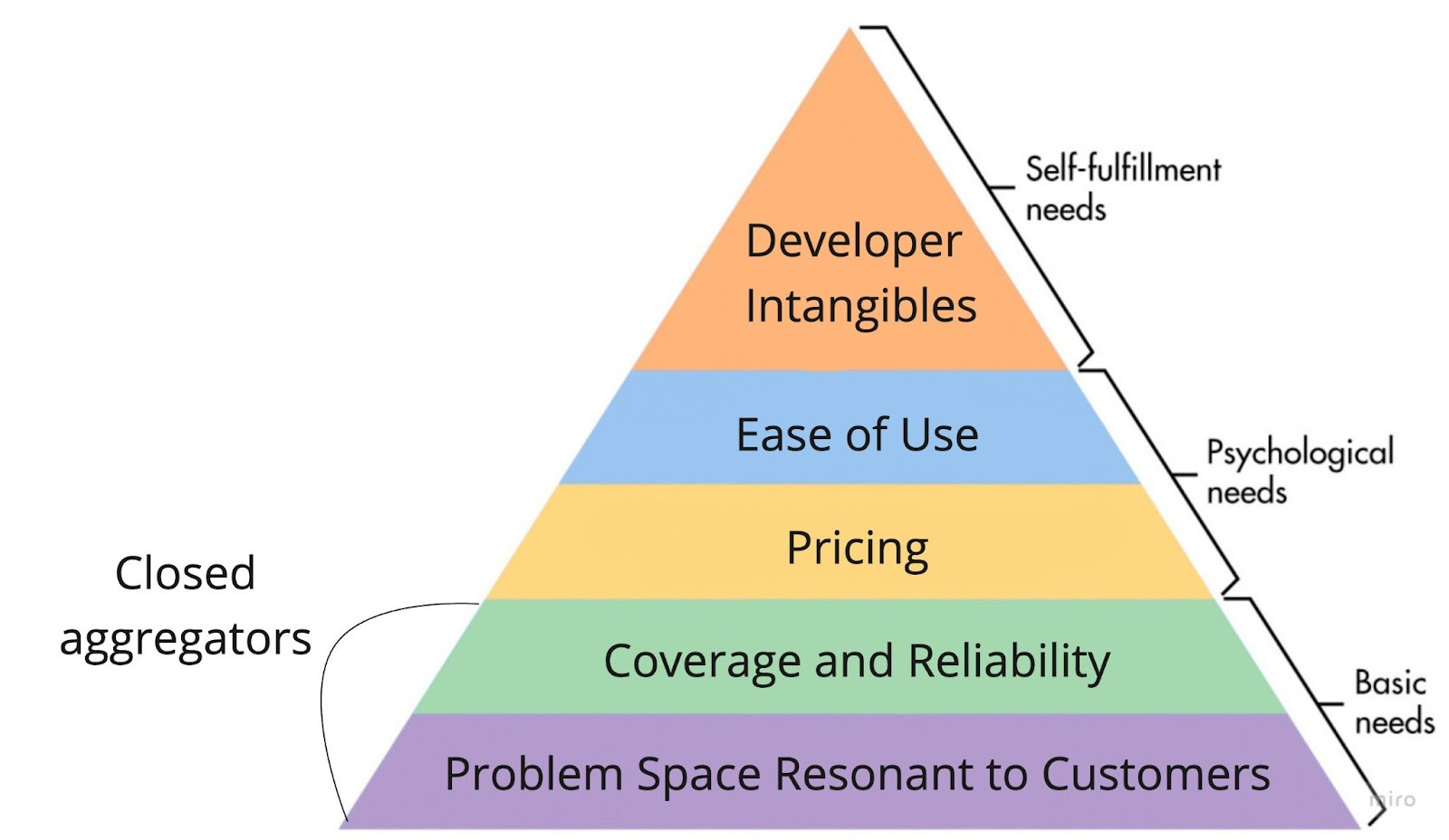
Closed aggregators are endlessly fascinating to me. They are functionally quite similar to the open aggregators above - pre-building and maintaining the connections, normalizing disparate content formats, and allowing developers to connect once for widespread access - but differ in that they rely on some B2B relationship with the data source that is being aggregated, either directly or via a customer relationship.
Let’s mince no words here - this is hard, gritty work. Their model is more time-intensive, but their potential is largely uncapped. At best, they are in the dirty, painful work of true network building. This is a game that takes time and effort - the delicate dance of partnership negotiation and incentive balancing takes patience and a steady hand, convincing stakeholders to participate and building towards ubiquitous usage. Done successfully, you become a powerhouse that is nearly impossible to disrupt - Visa, Surescripts, the telecom giants. There’s a high upside inherent to the business network builders if they can pull their lofty goals off - given the challenges of network building, these are generally winner-take-all markets.
Far more common, though, is to fall into the (still profitable but with a significantly lower ceiling) trap of adapter building, facilitating connectivity in a technical sense but not via a novel data-sharing agreement or set of unique business rules they define. Some of these companies simply connect applications within the context of a single enterprise, such as Zapier, Segment, Tray.io, Pipe17, or any number of other Customer Data Platforms (CDP) and Integration platform as a service (iPaaS) solutions. Over time, these companies build to many SaaS solutions’ APIs to allow plug-and-play connectivity for all the applications an enterprise might own, but they cannot and do not build a network, per se. Thus, I’m on the fence whether this lower bound of closed aggregators, the adapter builders, should count as API companies, given they’re sneakily just organizational connectivity management SaaS that happens to have an API.
Other closed aggregators fall somewhere in-between, facilitating connectivity across enterprises, but are still fundamentally reliant on the business relationships of their customers to actually turn anything on. There are a lot of companies that fall into this bucket across different industries - Redox, Modern Treasury, Violet, Noyo, Finch, and many more - and they’re all united by the fact that they are building B2B connections into a web of exchange, but only if a given partner has established a partnership with another organization in that web. Most have lofty aspirations to use the collective weight acting as pure play technical networks to eventually assert their own business rules and turn into a business network.

The unfortunate reality of most closed aggregator companies
It’s hard to differentiate these three sub-types (the adapter-builders, the technical networks, and the true business networks), especially since they may market themselves as what they aspire to be or perhaps even fail to grasp the limitations of their go-to-market and strategy. Fundamentally, they solve three similar customer problem statements of very different scope:
Adapter builders answer “How do I connect all the apps I own?”. They have built plugs to connect within an enterprise.
Technical networks answer “How do I connect my systems to my business partners’ systems with minimal effort?". They have built plugs to connect across enterprises quickly and easily. They may have pre-built pipes, but the use of those pipes is entirely predicated on business agreements outside of their control.
Business networks answer “How do I connect my systems to the systems of other businesses with minimal point-to-point business negotiations?”. They have built true pipes across enterprises for which they set the rules of engagement.
To further confuse things, companies can move between or offer services across these subtypes. Smart strategic minds will see the higher upside of network building and architect their offering to incentivize customers to purchase a network-oriented offering (“Come for the Tool, Stay for the Network” in Cold Start parlance). Given the challenges, enduring the long haul of collecting business agreements to scale requires finding that first atomic network and expanding from there. Sometimes regulation, competition, partnership structure, or other externalities will prevent an aspirant network builder from achieving their aim and box them as a purely technical solution. Some just like and are best at tool building, so they try to perfect that art.
Closed aggregators span a wide spectrum, but at best, they are world builders. The novel solutions via the networks they create at scale redefine how we interact as consumers and businesses. In a pre-credit card world, it was nigh impossible to imagine swiping a piece of plastic and paying via banks nationwide. They’re also notoriously tricky to build to ubiquitous coverage, requiring timing, skill, and luck. Thus, API products in this category often wrestle at the lowest levels of our hierarchy.
Examples
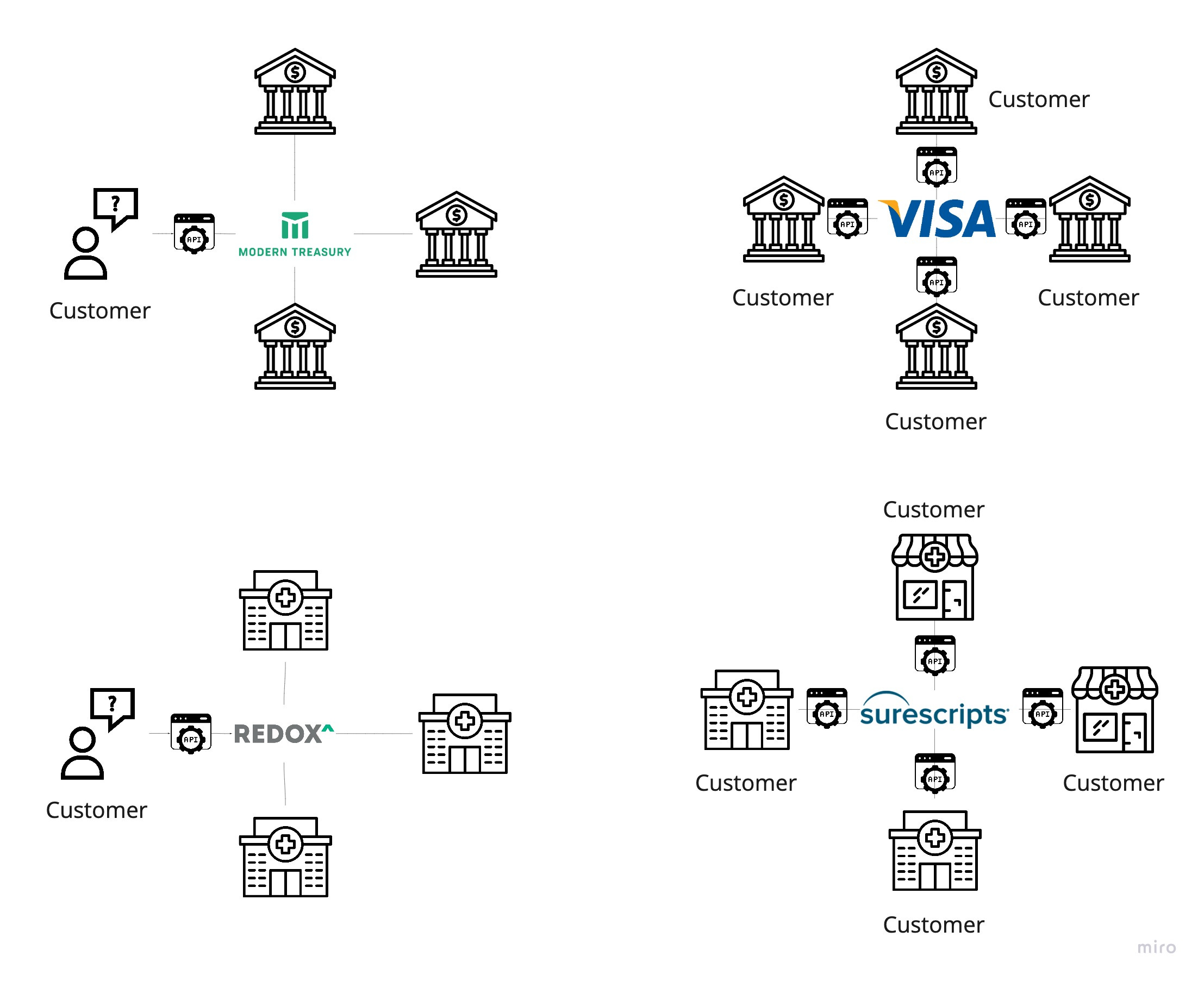
Financial
In terms of pure business networks, the well-developed and ubiquitous credit card networks (Visa and Mastercard) are the legacy examples. They’re not API companies in the modern sense but have inputs/outputs (technical connectivity points) as well as self-defined business rules. Thus, they represent clear examples of the upper bound / ceiling of what a closed aggregator can achieve and are worth noting.
Lots of intermediary API companies have popped up in this space - Unit, Bond, Synctera, Rize, and Treasury Prime. These Banking-as-a-Service middlemen are very similar to the headless banks we mentioned before but have negotiated specific agreements with sponsor banks to create and optimize the API experience for developers wanting to do those functions via an API. They’re a very limited form of business network closed aggregator, in that they offer functions via unique business-to-business relationships and normalize/improve the experience with an API. However, usually their aggregation is confined to a handful of sponsor banks at max. Most are somewhat constrained on how much "supply" they can ever end up with since these programs are difficult to set up and maintain. More detail on the space can be found here.
Going beyond BaaS, Modern Treasury is the cleanest example of a modern closed aggregator API company in this industry today. They help connect the payment operations of businesses across all industries to their bank partners (deep dive here). At first glance, they look somewhat like an on-ramp - they offer payments via existing networks like ACH or RTP. However, where BaaS vendors have a single or limited set of sponsor banks, Modern Treasury connects their customer businesses to the bank of their choice, thus acting as a closed aggregator between businesses and their banks. As a true technology middle layer, they not only work with more banks but also work with the largest banks in the world (like JP Morgan).
Like many closed aggregators, they hover between technical networks and business networks. For most of their bank partners, Modern Treasury has established technical connectivity previously on behalf of pre-existing customers. When they onboard a new customer, they must initiate an implementation via their business relationship with that bank, which can take some set-up time. However, some banks, like Increase, have an instant, self-service setup with Modern Treasury. This is a superior customer experience, so scaling this latter option to many banks is how they might level up to become a true business network closed aggregator, as Packy McCormick, author of Not Boring, articulates here:
Once enough big money movers use enough of Modern Treasury’s products, Modern Treasury could build its own “closed-loop” network through which businesses could move money to each other, from bank account to bank account, in real-time.
This is exciting (as are most analyses when the strategic direction is ambitious)! This is exactly the right strategy for a company in its shoes to pursue, at least in terms of the ceiling. It is also an unambiguously difficult path to navigate - aggregation of demand with a compelling product is only the first step. Utilizing that aggregate demand as a carrot or a stick to compel customers and their networked counterparts to move to a new paradigm and use your business rules is unique each time, with no repeatable playbook.
Payroll
Just as payroll data can be valuable to consumer-facing experiences, it can also power unique workflows across businesses. Finch and Merge exist to serve this need as technical networks, providing plugs into a wide variety of payroll systems for HR platforms, fintechs, insurance underwriting, and a variety of other cross-enterprise use cases. While Finch is hyper-focused on payroll, Merge appears to strategically be going broader, offering connectivity to other core systems that a business might have, such as CRM, applicant tracking, and ticketing. That sort of breadth is intriguing, but does give pause - it’s a common tactic of closed aggregators to market systems they have not pre-built, but feel confident in being able to connect upon customer demand. I also shudder a bit at the surface area of support needed to understand the nuances and maintain connectivity to such a wide variety of data types and systems.
E-Commerce
E-commerce seems pretty simple and straightforward in this modern era - in my simple brain having never actually used the tools, I imagine it’s a few clicks with Shopify and Instagram ads, and bam, you have a DTC brand with millions in top-line revenue.

However, no matter what it looks like, the truth is that every undertaking that humanity chooses to endeavor on is a neverending fractal pattern of complexity. Each new niche within an industry containing every smaller sub-niches, ad infinitum, leading to competition (both at the top level of e-commerce and levels of supporting systems) driving a fractionalizing rat race. This inherent intricacy means e-commerce is in fact hard, so if you’re selling goods on the internet with any meaningful scale, you have a lot of tools - Point of Sale, marketplaces, ERP, 3PL, etc. You could use a general-purpose adapter builder type of company (Mulesoft, Boomi, Tray.io, etc) to manage all of that, but they don’t “get” the industry. They haven’t built all the adapters to the e-commerce tools and they haven’t optimized the workflows for the specific personas of various employees within an e-commerce business. Thus, the existence of Pipe17 - it is an adapter builder style API company warranted by the deficiencies of cross-industry tools. As an adapter builder, the ceiling is limited here - it’s not a network and sits within the bounds of a single enterprise - but it’s illustrative of how industry-specific adapter builders can be viable even with behemoth iPaaS tools out there.
The next rung up in the API company typology, technical networks, has a few truly fascinating case studies - Rutter, Violet, and Stedi.
Rutter and Violet at first appear as pure competitors. They’re both aimed at aggregating the common e-commerce platforms - Shopify, WooCommerce, BigCommerce, etc - and providing a simple, normalized API for their customers to connect to. Both work similarly, having their customer merchants authenticate access to the e-commerce system they use. However, looking closer, they do not overlap but instead neatly parallel one another:
Rutter is selling their API to fintech companies looking to manage merchants (like Ramp) or financing/lending (like Kickfurther/Wayflyer). Given this focus on financials, underwriting, etc, they connect to e-commerce systems, but also accounting systems. Thus, their APIs are very heavily slanted towards pulling data and not writing back information or facilitating workflows.
Violet is selling their API to what they call “channels”. I struggled a lot more to grok who these customers were, but after poking around a lot on their website and DMing their CEO, these are the ‘new entrants’ to the next generation of e-commerce: large social networks, media publishers, blogs, creators, or any type of internet-connected experience. They’re looking to offer unified checkout orchestration to these customers, enabling them to embed e-commerce in their native flow. Their APIs go through a much more bidirectional exchange, enabling the full purchasing flow - listing products, listing deals, creating orders, and facilitating payment.
It’ll be interesting to see how these two technical networks grow. Selling e-commerce data access to fintechs and eventually, banks seems a bit easier on paper - smaller and faster sales, more customers, and a crisper market definition (I as a fintech or loan provider can self-identify as a potential Rutter customer more easily than I as a “channel” can self-identify as a potential Violet customer). On the other hand, Violet’s customers are big cuts - if they are installed with Instagram as the native checkout solution, it unlocks a lot of merchant volume. I do wonder if the quest for growth will eventually lead them into a true competition - Rutter has Thrasio (an e-commerce aggregator managing multiple brands) as a customer logo, which seems much closer to Violet's territory than the other customers.
A Brief Aside
Interestingly, there’s also Codat, who seems to be trying to do everything for everyone, all at once, pulling e-commerce and accounting data like Rutter, but also enabling push integrations with their “Sync for Commerce” feature. They also randomly have a Plaid/Truelayer partnership, which feels distinctly out of place as it co-mingles consumer-facing, open aggregator API flows with the closed aggregator capabilities.
Codat feels confused about who they want to be when they grow up. Success in startups is heavily correlated with focus - breadth leads to a lot of half-baked features and the dead weight of a higher surface area of ongoing support, so I wonder if some of their Product Managers should judiciously trim the fat a bit.
As a final example, we’ll talk about Stedi. Stedi plays on the edge of commerce and e-commerce, acting as a toolset for businesses to play with EDI (an ancient message format). Their evolution is particularly interesting for a variety of reasons.

In the context of this article, they now clearly market themselves as a technical network for cross-enterprise exchange, using verbiage of offering a “platform for business integrations” and “building blocks”, but this was not always the case. See this article about their 2020 raise, which clearly articulates a different vision than today:
Stedi is building a network of digital mailboxes for businesses to send transaction information and other business documents to each other quickly, even if one of the parties doesn’t use Stedi. The company specifically points to purchase orders, invoices, and ship notifications between suppliers and retailers.
Likewise, their website in 2020 heavily harped on the potential of the Stedi network:

Thus, they offer the relatively rare example of a company retreating from business network aspirations and doubling down on offering technical network tools and connectivity.
Insurance
Small businesses don’t just need payments and e-commerce integrations. They also need to be able to protect themselves from catastrophic loss and other contingencies through insurance. To facilitate those interactions, would you believe that several API companies are starting to emerge?
Insurance brokers have existed since the dawn of time (roughly) to aggregate different carrier offerings and present that menu to potential customers. However, that networked exchange is historically manual and analog, implementations repeated over and over for each broker-carrier relationship. Given that wherever we see this paradigm of undifferentiated but laborious implementations, we generally see a technical network API company, so it’s no surprise that Herald exists. Selling mainly to brokers (but also SaaS platforms and platforms trying to offer embedded insurance), it offers a single API to quote General Liability, Workers’ Compensation, Cyber, and Property insurance. It’s distinctly still a technical network, based on their FAQ, but one that does seem to have on-platform capabilities for participants to control their relationships:

I’ve never started a business (and thus never needed business insurance), but I think Herald seems pretty sweet (albeit I feel that way about most API companies and technical networks). However, I do wish they would open up their API documentation, as it’s currently stuck behind an “email us for access” gatekeeping process, which is a big no-no if you’re building a developer-first product.
On the other side of the indemnification spectrum, we see similar styles of companies for health insurance. Noyo and Vericred remind me a lot of Violet and Rutter above - technical network API companies that are fairly competitive on the surface and connect to a lot of the same source systems (health insurance carriers), but offer products with differing capabilities aiming to appeal to slightly divergent typologies of customers:
Vericred is selling its unified API to insurtech and digital health, offering connectivity to health insurance carriers. Their APIs are very heavily slanted towards pulling extremely detailed benefits data and not writing back information or facilitating workflows. They also have productized their offering for the source side, selling to carriers. This is a more viable strategy for legacy industries like insurance than it is for more tech-forward industries like e-commerce.
Noyo is selling their API towards a more focused set of personas - benefits administrator platforms on one side and the carrier on the other. Noyo is much more concentrated on a single workflow - the policy lifecycle - and helps with all bidirectional aspects entailed (group creation, member enrollment, and policy renewal).
Just like with Rutter and Violet, you have to wonder whether growth will increasingly pull these two into closer product feature overlap and competition. They share a number of the same customer logos today - Rippling, Gusto, and Zenefits. At some point, the uneasy truce may end as they strategically try to end multi-homing or as one of these customers pushes their vendor to broaden their offering.
One other fascinating tidbit here is the emergence of industry standards - the LIMRA Data Exchange (LDEx). There are too many standards to count in healthcare, so it may seem obvious to convene a council of competitors to build consensus-based formats when doing data exchange, but in other industries, this is rarer. LDEx is pretty new to the scene, with the first version announced in 2020. Both Noyo and Vericred participate in LIMRA alongside some other carrier and benefit administrator companies. As these standards mature, will the proprietary APIs of those companies be replaced? Or will LDEx simply stand to augment and ease the burden of their implementations with customers? My bet is on the latter - LDEx is still a bunch of gross XML, so one can imagine a continued appetite for easier-to-use JSON APIs.
Healthcare
Adapter builder style companies emerged early from the health tech primordial soup with the industry-specific moniker of “interface engines”. Aiming to match the variety of data formats and connectivity methods needed by EHRs and the constellation of surrounding systems within a given organization, they’re fairly pervasive across health systems, especially in the larger integrated delivery networks or enterprise-level institutions. These are industry stalwarts largely - Cloverleaf, Lyniate, Mirth, and Intersystems - with minimal new entrants disrupting their core business.
In terms of technical networks facilitating exchange between business associate applications and their health systems, Redox has stood bloodied yet resilient, watching as competitors like Sansoro, Bridge Connector, and Datica have fallen from grace due to bad strategy, fraud, and (worst of all) acquisition by an enterprise company, respectively. They’ve scaled out to ~3500 health systems and around 90 EHRs supported, wavering on the edge between technical and business networks - while they often reuse the technical connection to a health system, they still typically rely on the out-of-band business associate agreements between the application and that covered entity before enabling connectivity.
The much-hyped and absurdly well-funded NexHealth operates in this same liminal space, just further downstream. Their oft-critiqued technical approach of direct to database connectivity and disdain for health standards like FHIR differs dramatically from Redox, but, make no mistake - they are solving roughly the same problem as technical network API companies, just for different parts of the market (primarily dentists today but with a growing number of small practices running on low-end EHRs like eClinicalWorks). Their strategy has some huge upside, as they store and possess all of the data of the healthcare organizations they work with. It also has some monumental drawbacks and risks - the messy business of raw operational EHR tables is a service-heavy lift that cannot be automated and is a technique that simply won’t be possible with the larger EHRs.
Lastly, Health Gorilla’s lab order and results product is a technical network - they’ve successfully connected provider customers to many labs, but connectivity is dependent on individual business agreements between each provider and lab. Thus, it is not as simple as “connect to the API and send to every lab listed immediately”. Their tool simply reuses the technical connection to a lab and accelerates the process for a provider who wants to avoid HL7v2.
Similar to many of the technical networks in other industries, both of these companies sit at a crossroads: they can live their corporate lives churning out adapters and make a very successful business (a.k.a. pulling a Stedi). To transcend to the next level, though, they have to find a way to pull the business relationship into their ecosystem. Deft contract negotiation is certainly one simple path to this goal, with the right legal clause or paragraph unlocking the secondary use of data. Alternatively (and less creepily), productizing the interaction patterns and bringing the out-of-band business agreements on the platform can create a true cross-EHR marketplace function between apps and health systems.
Healthcare does have some pre-existing business networks (the “rails” fully outlined in “Ramps and Rails”) - Carequality and Commonwell for widespread retrieval of clinical documents, DirectTrust for pushing messages to doctors nationwide, PatientPing and Collective Medical for notifications of patient events, and of course Surescripts for e-prescribing. Just like we saw with payment networks, you have to squint your eyes to position them as API companies, as their formats for input/output are largely not developer-friendly JSON, but dense legacy standards. Regardless, they represent what the networks-to-be-built might be one day.
Some other newer health companies are angling to create true business networks worth mentioning:
Traditional Datavant for brokering de-identified clinical data between covered entities like payers and providers and non-HIPAA entities like pharma
Moxe Health or Datavant’s new Identified Switchboard for release of information between providers and payers.
Health Gorilla gets yet another mention, as they have products in multiple API categories. Their primary success comes from acting as a lab order/results technical network and also as an on-ramp and foil to Particle, for sure, but features such as on-platform referrals and secure messages signal their vision to build out their own business network. While I appreciate this ambition, their success would lead to our national network of exchange being named after an ape, which I’m not totally on board with.
Real network building is slow and hard, so it will be interesting to watch as these and other players continue to grow.
So what’s it all mean?

Yeah, that was a lot. Yet somehow you’re still here, having either poured through the full, complete picture with incredibly niche examples and spiraling tangents or skimmed this series to copy the diagrams and chuckle at the memes. Either way - props to you. Let’s bring it home.
Given that execution, marketing, and other intangibles matter just as much as (if not more than) conceptual moats, it’s possible to build great, even generational, companies with any of the four main categories of API company - headless, on-ramps, open aggregators, and closed aggregators. Across all, we see themes of technical arbitrage, the capricious nature of regulation, and similar tranches of competition. But each comes with a varying level of strategic defensibility and differentiation, so it’d be foolish not to understand the risks and value inherent to each model.
At the very least, it is my most sincere and deepest hope that having read this article, you’re able to metaphorically Will Smith the shit out of any founders, journalists, or VCs who inappropriately claim the “Stripe for X” or “Plaid for Y” mantle.

Again, given the length, tremendously grateful to the editors who helped out with this particular article, so here they are. Please click on their links and support their companies:
Ex Plaid and current Codat here. I thought I might share our learnings from 5 years of building SMB FinTech infrastructure and where we are heading as a result.
The fundamental challenge here is not actually aggregation. Plaid supports over 10,000 financial institutions in the US alone. Each of them have unique end user authentication protocols and data retrieval methods. Aggregating that data yourself is a nearly impossible task for any developer trying to build a FinTech app that needs this kind of connectivity.
However, when it comes to small businesses there are a relatively small number of data sources that actually matter, most of them have very mature developer experience programs and very standard authentication protocols. There are at most several dozen SMB financial SaaS platforms globally that really matter and many of the category leaders have upwards of 50% market share in their core geos. Unlike banks, companies like Intuit, Shopify and Stripe have hundreds of engineers, PMs and DevRel folks supporting their APIs. If you’re building an SMB FinTech app, aggregating this data is absolutely necessary. But it's also not especially difficult to do it yourself, particularly at scale.
We think the real problem is interoperability.
Small businesses use dozens of different types of SaaS applications to run their business and getting them all to work in concert is a real challenge for developers trying to bring new financial products to market for SMBs. Different applications are used for different financial operations - bookkeeping, sales, ecommerce, billing, bill payment, payroll, advertising, forecasting, banking (small businesses have bank accounts too, yo!), etc., etc. Aggregating each of these categories is pretty straightforward, and we do that too (except banking, hence our integrations with Plaid and True Layer). But getting them to work with each other is anything but.
Finance and operations teams spend hundreds of hours with these platforms and it's really difficult for developers to build integrated and automated solutions on such a fragmented ecosystem. So is getting a comprehensive, accurate and real time understanding of the health and performance of that business.
And if that weren’t bad enough, each of these platforms have their own developer registration process, app approval requirements and marketplace strategy. Unlike consumer financial data, there is almost zero regulatory framework guiding how, when or even whether this data can be accessed by third parties. There are almost no standards governing the rights of small businesses to share their data nor the responsibilities of those with whom they share it. Integrating with these APIs is often easier than simply getting access to them in the first place.
These are the problems that Codat is trying to solve. Most of SMB FinTech is converging on a handful of core use cases, and everyone wants to be the financial operating system for their slice of the market. Codat wants to be the core infrastructure on which those operating systems run.