


Indiana Jones and the Personal Health Record
The future of consumer healthcare and sequel to Crystal Skull borrows heavily from our stories already told in financial technology

Spinning off from this Twitter thread and others to compare healthcare and banking.
The Personal Health Record is a healthcare holy grail for many. The utopian vision of patients fully in control of their health data plays to the individualism inherent to the American way of life. With the rise of the crypto community, blockchain bros are captivated with a similar concept of decentralizing and democratizing our data.

Recent regulatory guidance stemming from the 21st Century Cures Act and the resulting ONC Final Rule support this vision, at least at first glance. It aims to open up consumer-facing technology with standard FHIR APIs and to unify previous attempts for patient access, the C-CDA download of the View Download Transmit provision of Meaningful Use 2 or the disparate hodgepodge of APIs exposed via Meaningful Use 3.
Logically, consumer tech companies want in. Google, Microsoft, and many others have tried prematurely and failed to capture this market (“to be early is to be wrong”). Apple has Health Records, arguably the best product available in this niche. You have to imagine Facebook is also eyeballing those APIs to help drive their recent preventative health efforts around vaccines.
If the PHR is the holy grail and the finance community is Walter Donovan, then we (the healthcare community) are Indiana Jones in the Last Crusade, standing next to the Grail Knight and trying to pick the right cup. We’ve seen the fintech community go charging ahead and choose the wrong cup. Will we continue down the same path? Or will we make the same mistakes despite their example?

Taking a step back from the metaphor, let’s discuss the history and current state of Personal Health Records (Wikipedia has a surprisingly solid primer). Conceptually, the idea is simple: an app for consumers to have a personal record of all their healthcare data. You’ll commonly hear the word “longitudinal” tossed around in this space, which is somewhat buzzwordy. Longitudinal in other contexts just means “gathered over long times”, whereas here it’s conflated with “across many sources” as well. Not sure why latitudinal or lateral health data got the shaft there.
Regardless, aggregating the medications, allergies, problems, and other clinical information available at the various healthcare institutions a patient might visit is not a new concept. The concept took off in the 2000s alongside its financial sibling, Personal Finance Management. PFM is pretty well known by consumers at this point, with Mint dominating the national consciousness in that regard due to a superlative user focus during its launch and growth. Other players, such as Personal Capital, YNAB, EveryDollar and PocketGuard have edged into this space with different marketing, focus, and truly differentiated features like not being part of Intuit.
The value prop for PFM apps is pretty straightforward. Banks’ own web portals and mobile apps offer convenient ways for consumers to see and take action on their accounts and balances. However, consumers often use many financial institutions, so each portal is a small snapshot of the total picture. By pulling in and summarizing all of a consumer’s account information, these tools purport to be able to help them manage their budgets and planning better.
PHRs purport to offer roughly the same in health. The ones on market today focus on aggregating clinical data from healthcare organizations (HCOs), payers, and even consumer devices in order to provide the “full picture” of one’s health. There’s strong verbiage of “patient empowerment”, “getting in control of your health”, and “personal care coordination”. Given the prominence of Mint in finance, it’s seemingly very appealing, with some nice raises by PHR companies like PicnicHealth.
Unfortunately, that promise is somewhat bogus, because it ignores human nature and incentives around health. In order to be successful, tools need to solve consumers’ problems. Personal Health Records solve the wrong ones.

The consumers that care about and manage their health are not your average American. Your average American generally mismanages the hell out of their health, which is why we perform so poorly in regards to health metrics. We don’t eat right, we don’t work out enough, and we don’t have the right checkups. If these consumers do happen to use technology, they primarily seek additional convenience out of any tools or applications they use for their health, helping them achieve good outcomes (spend less money, do the right appointments, perhaps be healthier) with minimal effort on their part. A PHR doesn’t help them achieve these goals in a concrete way.
Extremely healthy patients have a slightly higher incentive to track their health. Whether they follow a strict diet or work out regularly, aggregation of data and metrics helps them achieve these goals. However, the data sources are primarily ones close to that lifestyle - Fitbit or other consumer fitness electronics, diet management applications, etc. The clinical data aggregation of PHRs is not necessarily core to solving their problems.
Extremely sick patients, especially with chronic conditions, are the main benefactors of PHRs. Tracking medications from multiple providers, understanding the outcomes of visits at various practices, and building the overall narrative becomes increasingly important as the frequency of engagements increases across disparate sources.
Overall, by overlaying a bell curve to represent how the population is spread across these groups, the market you address ends up looking like this:
The market and patients you’re serving become increasingly geared towards the long tails of the population. As a consumer-facing product, that’s often not ideal. Even worse, there are a number of compounding factors to make your market increasingly fragmented and success trickier:
Technological savviness: Will older consumers be aware of and capable of using your application?
Split tails: The needs of either of these tails are drastically different, diversifying the necessary MVP feature set you need to service both and making the application more complex. Healthy people look for features that support health maintenance in their day-to-day living, via the aforementioned fitness and diet trackers. Sicker patients look more for clean clinical data aggregation.
With this in mind, it becomes clearer that successful patient-facing health products win by either:
1. servicing the bulk of the bell curve’s needs. This is what general-purpose PHRs like Apple Health Records or OneRecord aim towards and are best in class for.
2. creating a premium experience focused on specific very sick patients. This is what PHRs like Ciitizen or PicnicHealth are trying to do.
That bulk of the bell curve cares little about their clinical data, but wants convenience out of the health experience, optimizing for:
Provider discovery and selection
Appointment management
Communication with providers/health systems
Billing and payments
In order to understand whether those goals actually can be achieved, we can start by looking at the technology underpinning PFMs and PHRs.
How Consumer Data Aggregation Works
Functionally, both PHRs and PFM use two technologies to aggregate data - screenscraping and APIs. Screenscraping is the older of the two, relying on consumers supplying the vendor with their organizational portal credentials so that the app can log into the portal, click through to the right screens, and scrape off data from various web pages or downloadable assets. It works fairly effectively, having been refined over the years. However, data holders (banks) criticize the security risks of these apps holding onto consumers’ credentials, as well as the server loads it puts on their infrastructure. While innovative companies have sexily rebranded this technique under the umbrella term of Robotic Process Automation (RPA) to avoid that stigma, not much has changed. This old method of data exchange still underpins a large portion of reading information from sources.

Application Programming Interfaces are a different beast. Savvy US banks, seeing the growth of data-hungry consumer-facing fintechs and tired of screen scrapers destroying their servers (example), have begun to expose APIs to control and even monetize client systems’ information access. This benefits banks in that they can expose a subset of the data they possess and limit data access to the applications they see fit. Ostensibly, these decisions are framed as being in the consumer’s best interest, but, more probably, these actions occur to limit the competitive threat of fintech startups. In any case, this switch to APIs does at least benefit the consumer in terms of reducing their exposure by not storing their credentials on the application side (if my user name and password are stored only with the bank and not also in the database of every app I use, I have less risk of credential theft).

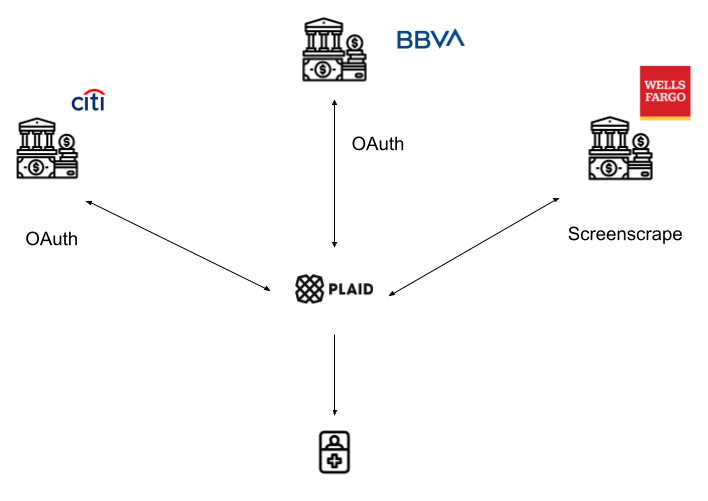
Personal finance applications may possibly access these APIs themselves and/or develop screenscraping capabilities, but that’s generally not the case. In between the PFMs and banks currently lives a number of data aggregators. These aggregators are technology vendors who simplify the experience for developers by creating APIs to frontend the screenscraping and disparate API support across all their connected banks. The most well-known is Plaid, but Yodlee, Finicity, and MX all play in the space in the US (with a variety of similar companies in other countries). Some basic compare and contrast on those companies here.
The value prop of aggregators to developing applications is simple. Instead of each consumer application building unique connections to dozens or hundreds of banks, they provide broad, uniform access via a single API to developers, plus value add services like data cleansing (turning codes and acronyms into real-world names of businesses, for instance) to ease the development experience.
We’re seeing massive interest in these aggregators from major legacy network players. Visa tried to acquire Plaid for 50x revenue ($5.3 billion) in January 2020. Mastercard, not one to be left behind, followed suit by buying Finicity at roughly the same multiple ($825 million). Given that Yodlee was snapped up by Envestnet, you have to imagine any remaining players are looking at MX salivating. In any case, most of the verbiage used in these acquisitions’ press releases center around Open Banking (an EU driven regulatory mandate which isn’t really a thing in the US at least in terms of current regulation). That benevolent stance seems unlikely to be the primary motivator for acquisition; rather, there’s an absolute thirst for their unparalleled consumer data, possibly in order to build consumer identity. Tom Noyes had a nice post about those aspirations here.

Digital Health Aggregation
Not to be outdone, healthcare has equivalent data aggregators in Human API, 1up Health, OneRecord and Apple Health. Like their fintech brethren, these companies offer a single API utilizing consumer (patient) credentials to authenticate and then pull down available information, making it easier from consumer-facing companies (like PHRs) to focus less on building out thousands of connections to healthcare systems and more on their end user-facing software.

However, the differences in the regulatory decisions between fintech and health tech (which weirdly mirror one another) have profound effects on the overall landscape:
In fintech, the European Union leads the US.
The 2015 European Union Directive, Payment Services Directive 2 (PSD2) was designed to ensure that banks create mechanisms to enable third party providers to work securely, reliably and rapidly with the bank’s services and data on behalf and with the consent of their customer.
While not explicitly designating a particular standard, APIs were/are commonly seen as the path to meeting this regulation, leading to disparate formats and authentication methods
2018 UK Open Banking regulation further defined the exact API formats (although only requiring it for the largest banks)
The US has no equivalent legislation, so although some domestic banks have exposed APIs, Plaid and others must have robust screenscraping capabilities to be successful.
In healthcare, the US leads the European Union¹ :
Meaningful Use moved to Stage 3 (MU3) in 2015, the Centers for Medicare and Medicaid Services (CMS) added APIs (application programming interface) as an alternative or complement to patient portals.
While not explicitly designating a particular standard, EHRs had to create some sort of API, leading to disparate formats and authentication methods
The 2019 ONC Final Rule of the 21st Century Cures Act further defined the exact API formats (FHIR R4)
The EU has no equivalent legislation, so although some European nations have local legislation (NL with Medmij, for instance) and some healthcare organizations have exposed APIs, for the time being, screenscraping is still necessary to be successful
¹ - Wow, that sentence was fun to type. Might be my first time ever putting that series of words together and possibly only scenario that’s true unless we’re talking about the total cost.

So given that there’s been more regulation to expose open APIs in the US for health, the situation should be pretty good for data access, right? Unfortunately, while the regulation lays a solid foundation, a few aspects still leave us in a slightly disjointed, interim scenario.
First, MU3-inspired API implementations were inconsistent and varied across EHRs and healthcare organizations, to the point that some aggregators chose to continue using screenscraping to acquire patient documents (CDAs) from the portal. While the incoming ONC Cures regulations are designed to curb the gaps/weaknesses of MU3 regulations, they are still new and mostly “work to be done” for EHR vendors.
Secondly, the data set covered by the ONC regulation is limited to U.S. Core Data for Interoperability (USCDI), which isn’t inclusive of all data recorded for a patient. In fact, it’s almost identical to the CDA data that was already accessible through screenscraping. The USCDI is iterating year over year through industry feedback, but far too slowly. Although a subsequent deadline of full EHI (electronic health information) export will drastically increase the exposed data set for a given patient, that data is not required to be in any particular format or codification, almost assuredly leading to tremendous variance across vendors and hurting its usability.
Lastly (and most importantly), the new regulation does nothing to further the pushing/writing of data back to the health system. It’s simply a mechanism for aggregating clinical data (and only a subset, at that). For applications that want to send information back to health systems without a BAA, the only available option is the DirectTrust network via a HISP (which very few PHRs have actually capitalized on using to date). While API-based write back may open up in the future in regards to suggesting updates to clinical data such as allergies or medications, I’d expect healthcare organizations to strongly push back on patient authentication allowing for open scheduling capabilities. To do so would allow their main resource (provider capacity) to become commoditized supply, allowing an aggregator to own the patient relationship and demand. History has not favored incumbents that have had their supply modularized and aggregated.
PHR Problems
With this technological backdrop in mind, we can circle back to the original hypothesis.
…successful consumer facing health products win by either 1. servicing the bulk of the bell curve’s needs or 2. creating a premium experience focused on specific niches.
Knowing that the APIs available (whether through a data aggregator or not) only pull in a subset of clinical data and cannot write back to the health system, option 1 is simply not possible. None of the tasks that the average patient finds inconvenient and would benefit from are improved:
Provider discovery and selection - While USCDI/EHI does include the practitioner resource, this is for understanding the patient’s care team at a given institution and doesn’t help with determining what provider is best to go to.
Appointment management - USCDI/EHI doesn’t include available slots for scheduling and the APIs do not allow for writing back appointments.
Communication with providers/health systems - The APIs do not allow for writing back to the chart or communicating with hospital staff.
Billing and payments - USCDI does not return information related to bills or patient payments. This might be addressed with the later EHI deadline.
Until we start to resolve the issues of the average patient, the upside and impact of patient-facing applications are handicapped. Standalone PHRs will only be a sad shell of their HCO-tied patient portal brethren, suffering from lesser capabilities and also reduced distribution channels. For specialty PHRs looking to help the neediest patients, USCDI is far from sufficient, missing major data like cancer staging information.
Additionally, the mechanics around monetization are tough. In health, patients expect these services to be free. The value prop for payers and employers is limited at best, and a PHR that’s sold to a provider is a patient portal. It’s no wonder that many PHRs gravitate towards pharma, who shows an unending appetite for patient data of any kind.
Who wins?
Despite this, our collective national investment into patient-authenticated APIs does drastically help some parties, though.
Traditional Patient Portals
If I’m a hospital executive and I’m thinking competitively, I may see PHRs as some sort of threat. I’d ideally like to own the touchpoints with the patient and help them navigate the experience. Perhaps previously I just tried to block that data flow. Given that’s no longer allowed, the next logical move is to keep parity with these alternatives, while optimizing the unique advantages that cannot be replicated.
Thus, the first of the major beneficiaries of the new regulation and available patient-facing APIs are forward-thinking traditional healthcare organizations that effectively utilize the newly ubiquitous patient-authorized endpoints. Patients will continue to use the health system patient portals that offer scheduling, billing, and deeper functionalities, especially if those same portals can aggregate the external data via the new regulated APIs. Epic’s MyChart is already allowing customers to link their portals at other institutions, giving them the benefits of the PHR (all the clinical data), but also of the patient portal (the actual administrative things people want to do). Any EHR that’s viewing the regulation as compliance (fielding inbound requests) is missing the massive opportunity for an improvement to their patient portal experience.
Back in our fintech parallel, we see this trend in banking too. Given that Mint has languished quite a bit and other pure PFMs have failed to capture the attention of the general populace, we see banks themselves starting to pull in external account data via aggregators like Plaid.

We also see PFMs start to pivot to become “neobanks”, partnering with traditional banks or even becoming a bank unto themselves, despite the regulatory challenges. This trend is identical to the one I wrote about in my last article, where patient-facing applications begin to add providers and traditional care, morphing into covered entities over time.
Insurance Companies
This article isn’t intended to explain HIPAA, as I am not a lawyer, but to drastically oversimplify that sprawling and influential regulation: there are two types of people in healthcare - those that can exchange patient data without authorization and those that can’t.
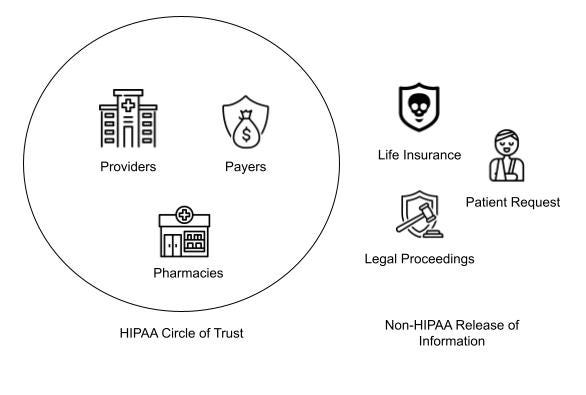
Whether it’s life insurance getting your medical records to understand the risk when underwriting policies, your lawyer grabbing them to prove your malpractice suit, or the Social Security Administration needing info for disability claims, the non-HIPAA actors need express consent to get that information. Prior to patient access APIs, that process has historically been expensive in terms of time and dollars. Most hospitals have a Health Information Management (HIM) department with staff dedicated just to facilitate this process. Entire EHR business units have been spun up to digitize the paper process (while taking a piece of the proceeds).
The pain of life insurance, lawyers, or the SSA gets better with this technology. With ubiquitous patient authenticated APIs, pulling patients’ records is a “free” process, assuming the patient remembers their login credentials. So life insurance can bake this step into their registration flows, embedding this capability and allowing their customers to gather the data they need to underwrite. Everybody wins.

We saw a similar process in banking with lenders underwriting mortgages. As Plaid’s APIs have become broadly available, the “upload all your bank documents” is increasingly replaced by a “pull in your account data” steps, reducing the burden on the lenders to collect and verify that data.
Embedded Health
In banking, the concept of Embedded Finance is growing in popularity, where non-financial companies take the different functions that used to be solely the domain of a bank or financial institution, such as lending, payments, and embed it at the right contextual moment in a workflow.
It’s finance that shows up just when you need it.
Uber or Lyft are two common examples of embedded finance, as they offering various financial products (e.g., debit cards, instant payouts, digital wallets) to both customers and drivers . You don’t have to cut a check or jump out of the travel workflow to your bank to pay; these financial functions are built directly into those non-financial applications in the right context, reducing friction for you as the user. There are numerous ways to add financial tasks and data as a seamless part of the app experience and they’re becoming commonplace to the point you may simply expect them as table stakes.
So, with that in mind, I say, if fintech can do it, why not us? The equivalent in healthcare feels like a logical outcome and evolution of patient access APIs, where small, contextually appropriate parts of healthcare information are embedded in consumer touchpoints. Dietary regimes pulling your allergies, medication management apps showing your medications, or Levels/Whoop/Peloton pulling select diagnostics all seem to fit this paradigm.
Beyond that, consumer touchpoints with high innate distribution may also start to utilize embedded health. We’ve already seen Facebook add some vaccination reminders into their notifications and tout the billions of lives they touch. It would be logical to see them reduce manual input and automate that more with embedded health.
When an app has authenticated data as an extra feature alongside its core offering, the value add is nice and appreciated by power users; when it’s the main draw and reason for patients to use an application, it’s a harder sell.

Do it for Shia LaBeouf

If you have seen the Last Crusade*, it ends with Indiana choosing to leave the grail behind, eventually getting to fight the Soviets, dig up alien corpses and hang with Shia LaBeouf. While the chances of your patient-facing application idea resulting in similar LeBeouf heavy experiences are low, consumer health should still follow in Indiana’s footsteps, leaving the PHR behind. The role of the pure-play data aggregator is missing the mark, but the ubiquitous access coming will power a new wave of health innovation. Embedded in the consumer experience, this next frontier of digital health will finally bring healthcare to parity with our fintech peers.
*If you haven’t seen the Last Crusade, you are most likely Gen Z and I encourage you to get off Tik Tok now and watch it.
Big thanks to Colin, Garrett, and Jonathan, very talented editors extraordinaire.
One of the best deep dives I have read on this problem. Wish I read this before launching my MVP. The honest truth is that the avg user does not care about their health to even be overly bothered about their records. If one is to innovate in healthcare, you are better off building something that empowers providers.